こんにちは、ひろかずです。
突如として現れた生成AIについて、さまざまなステークホルダーを巻き込んで議論や検討をしたい(せざるを得ない)のだけど、そもそもエンジニアや非エンジニアを含めた関係者のイメージや目線をどうやって合わせていこう?という声が聞こえてきたので一筆書きます。
tl;dr 的な何か
- 生成AIってどんなものなのだろうという状態で議論しても、各ステークホルダーの注意するべきポイントが漠然としちゃいますよね
- 生成AIを人に見立てて考えると、意外とイメージが付きやすいんですよ
- いい機会なので、人に対して暗黙的に行っているトラストを言語化して、生成AIに当てはめてみました
なぜ目線合わせが必要か
- そもそも、生成AIは全く新しい何かのように見えており、概念から把握することが必要と思われ、議論をはじめる以前の状態であることが予想されます。
- 生成AIはどのようなものであるという概念を目線として合わせることで、各ステークホルダーが自身が責任を持って考えるべき観点を把握し、議論できる下地を作れます。
目線合わせ - 「生成AIを人間と見立てる」
- 生成AIの使われ方を振り返ると、プロンプトに指示や入力データを口答指示のように渡し、生成AIは学習モデルに基づいて処理をし、生成AIからプロンプト入力者に対して結果を返すという構図になります。
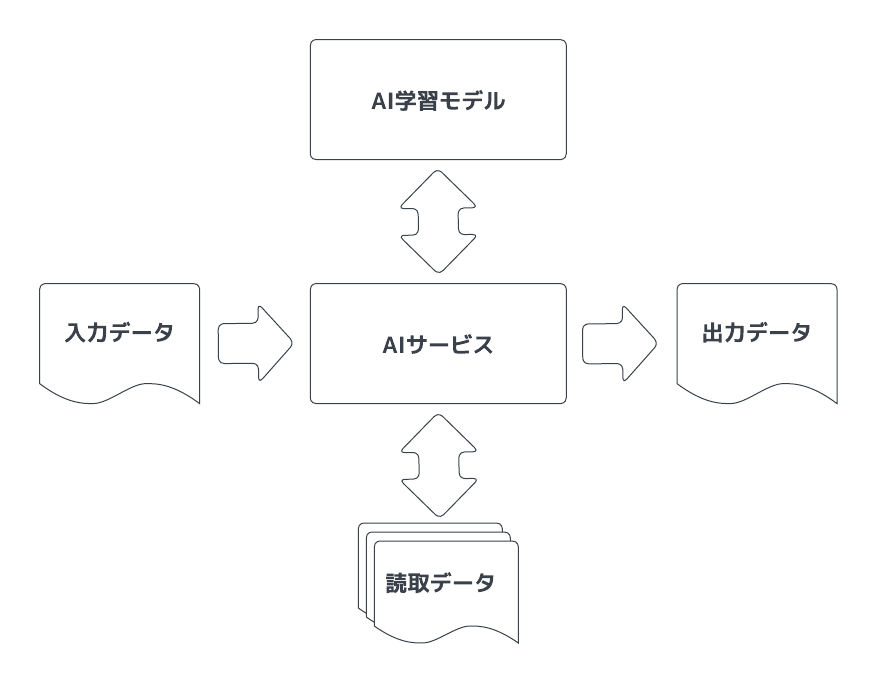
- この構図は、会社の同僚や部下、委託業者やコンサルタントに作業依頼や問い合わせを行い、結果を受け取るという構図に非常によく似ています
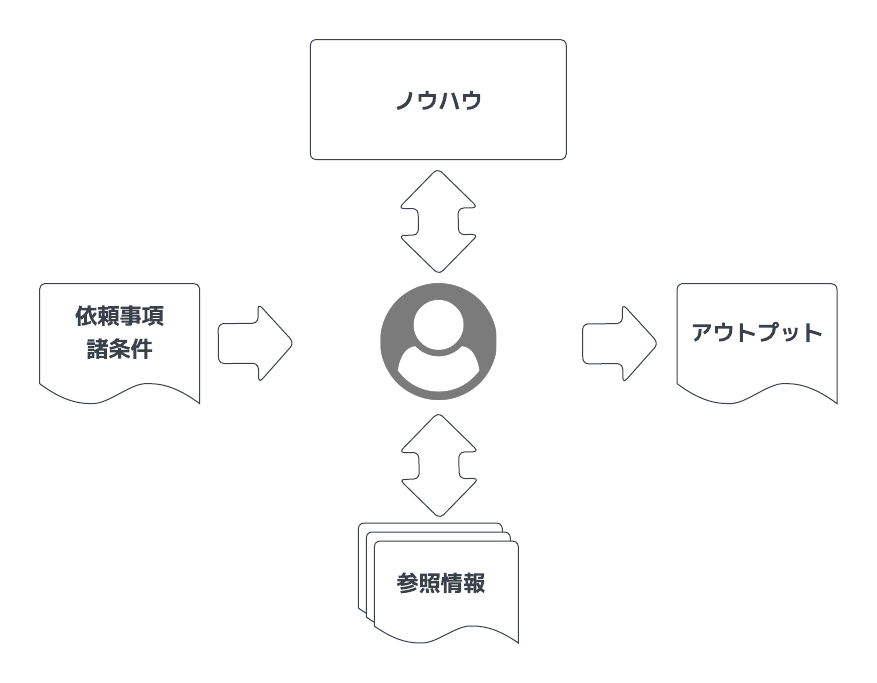
目線合わせ - 「生成AIを人と見立てるとして、そもそもこれまでどのようにトラストを積み上げてきたか」
- 人は、だれかにに何かを依頼する時は、確からしさの積み重ねを以て、この人にお願いしてもリスクを受容できる範囲にコントロールできるか?ということを確認しています
- 人にお願いをする時に暗黙的に行っていることを言語化してみましょう
この相手がどの程度信頼できるか?
- 人的スクリーニングに近い話ですが、一般企業では以下のことを行っていると思います
- 入社プロセスで、反社チェックや卒業証明書(経歴の確からしさ)のチェックを経ている
- 信頼できる上司や同僚からの紹介や実績がある
- 取引先の銀行口座や過去の取引履歴
この相手に渡していい情報か?
- そもそも社外の人に社外秘の情報を渡していないか
- あらかじめ定められている取り扱い方法に準拠して取り扱っているか
- 個人情報は、収集時に第三者提供に関する条項があるので、それに適合し、目的の範囲内で利用しているか
- 個人情報は、社内の取り扱いルールに適合しているか
渡した情報はどのように取り扱われるか?
- 契約で以下のような縛りを入れていることでしょう
- 第三者への引き渡し
- 依頼した目的のためだけに利用し、目的外の用途での利用の禁止
- 契約終了後の廃棄
この相手が作った成果物はどのように取り扱われるか?
- 契約で以下のような縛りを入れるていることでしょう
- 所有権や著作権の所在
- 第三者への譲渡の禁止
この相手が何かやらかした時に、どのようなことができるか?
- 秘密保持契約には損害賠償請求が言及されており、抑止力となります
この相手が作った成果物をどの程度信用するか?
- 参考程度とするか、何かのエビデンスとするか、重要な意思決定のインプットにするか、相手の信頼度とそのほかのパラメータを総合的に判断して決定しています
目線合わせ - 「生成AIを人と見立てた時に、生成AIのトラストをどう考えるか?」
- 少し長くなりましたが、生成AIを人と見立てた時に、生成AIのトラストをどう積み上げていくのかを考えていきます
この相手がどの程度信頼できるか?
- 雨後の竹の子のごとく様々なサービスが出ていますが、運営している企業そのものの信頼度が基点の一つになります
- 一般的なアプリケーションの場合、実行ファイルの証明書が署名されていることやドメインなども判定の要素になります
- AIサービスを実装・提供している側がどの程度説明でき、客観的に評価できるかもポイントになるでしょう
- これらの観点を基に、ある程度の検討のテーブルにのせて良いリスト(脳死して信用できるホワイトリストではない)を用意すると、検討のリードタイムが少し短縮できそうです。
この相手に渡していい情報か?
- この部分は、人やSaaSを利用する時と大きな違いはないように思えます
- 社外の人に社外秘の情報が渡らないようにできるか、それがどのように担保されているかの説明を果たすことができるか
- あらかじめ定められている取り扱い方法に準拠した取り扱いになっているか
- 個人情報は、収集時に第三者提供に関する条項があるので、それに適合しているか
- 個人情報は、社内の取り扱いルールに適合しているか
- 個人情報の処理方法や利用するツール、取り扱う場所などの規定に抵触するか
渡した情報はどのように取り扱われるか?
- 生成AIサービスに対して、個別に契約で縛ることはできません
- 利用規約や設定にて、提供した情報の取り扱いや廃棄についてどのようになるかを確認し、説明できるようにする必要があります
- 利用規約や設定にて、提供した情報がAIサービスのモデル学習に利用されるのかを確認し、説明できるようにする必要があります
この相手が作った成果物はどのように取り扱われるか?
- 生成AIサービスに対して、個別に契約で縛ることはできません
- 利用規約や設定にて、生成したアウトプットがどこに残留し、どのように取り扱われるかを確認し、説明できるようにする必要があります
- 利用規約にて、生成したコンテンツの所有権や著作権の所在、商用利用の可否を確認し、説明できるようにする必要があります
- 用途によっては、生成AIサービスの利用者が生成したコンテンツの著作者となれるかが確認のポイントになり得ます
この相手が何かやらかした時に、どのようなことができるか?
- 生成AIサービスに対して、個別に契約で縛ることはできません
- 法的に解決するケースを想定して、利用規約にて訴えを起こす裁判所の所在を確認しておきましょう
- 一方で、やらかした事実をどのように確認できるのかという点は気になるところです
- 突き詰めると、ニュースにならない限りわからないのではないかとも思えます
- 訴訟の実現性が低ければ、リスクが低いユースケースであれば、この部分は目をつぶるという判断もありそうです
この相手が作った成果物をどの程度信用するか?
- この部分は、人やSaaSを利用する時と大きな違いはないように思えますが、成果物を信頼して利用するために利用者が行う部分について考慮する必要があります
- 参考程度とするか、何かのエビデンスとするか、重要な意思決定のインプットにするか、相手の信頼度とそのほかのパラメータを総合的に判断して決定していきます
- 成果物の裏取りや正確性の担保は、利用目的の重要度に応じて、利用者側は必要な分だけ積み重ねる必要があります
- 出典が提示されることも重要ですが、出典がそもそも信用できるかという点と、出典を正しく読み解いているかは、利用者が担保する必要があります
- 計算している場合は、計算ロジックが検証可能であるかという点も気になるポイントです
- この部分をキーにして、生成AIを使うべきか否か(向き、不向きとも言う)を考えてもよさそうです
おわりに
- 漠然と生成AIについてたくさんの散在する情報を読んで考えるより、どのようなものを相手にしているのかがわかってきたのではないでしょうか
- 見方によっては、これまでなんとなく曖昧にしていたところが、改めて突きつけられる格好になっているとも言えますね
- 生成AIを人と見立てることで、生成AIサービスそのものに対する捉え方や、各ステークホルダーが注意すべきポイントが考えやすくなったと思います
- 困っているどこかのだれかの助けになれば幸いです
今日はここまでです
お疲れ様でした