
こんにちは、ひろかずです。
AWSが開催する、初のセキュリティ特化型カンファレンスre:Inforce2019に行ってきたので、一筆書きます。
ひろかずは、英語のヒアリングが非常に苦手なのですが、パッションだけで参加してきました。
初めて使う様々なツールを駆使しての執筆になりますので、いろいろご容赦ください。
tl;dr的な何か
- Amazon SageMakerコンポーネントのセキュリティー設定の説明と高度に規制された環境における主要な統制について
- Vanguard社の要件を題材にしながら、実装を深掘りした解説をしています
背景
Vanguard社は世界最大の投資会社の一つで、低コストの投資ファンド、TEF、アドバイス、関連サービスを幅広く提供している。
SageMakerとは?
概要
- フルマネージドなMLサービス
- モデルのビルド、トレーニング、評価、導入
− 最適化されたMLアルゴリズムとフレームワーク - 自前のアルゴリズムとフレームワークのサポート
SageMakerの典型的なライフサイクル
ビルド
- ジュピターノートブックベースの環境
- データ探索・準備・分析
トレーニング
- シングルインスタンス、またはクラスタでトレーニング
- メトリクスを使って、モニターと分析
- 増分/ハイパーパラメータトレーニング
評価
- "Holdout set"を用いたオフラインテスト
- 実働データを使ったオンラインテスト
導入
- プロダクションバリエーションを持つ永続的なホスティングエンドポイント
- バッチ変換

Vanguard社の主要要件
- 転送時、保存時の暗号化
- パブリックインターネットへのアクセスは行わない
- 全てのアクションは監査できる
- CI/CDベースのデプロイ
- ITサポートの最小化
- データサイエンティストが簡単に扱える
アーキテクチャの深掘り
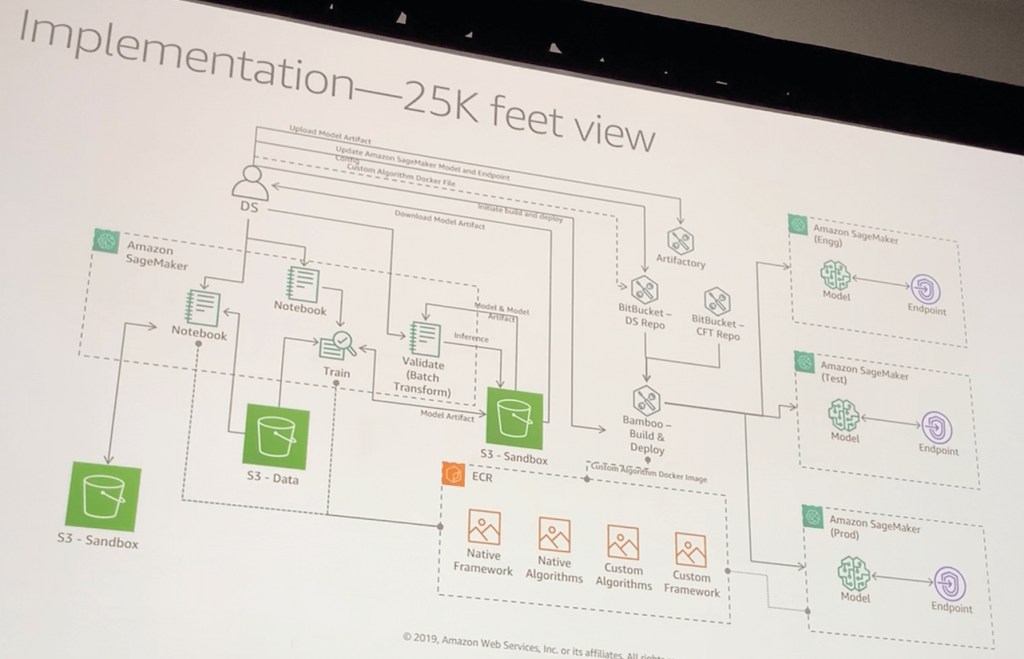
一般的な実装
- NoteBookにIAM Roleを割り当てる
- トレーニング用とValidate用のNoteBookを用意する
- トレーニング用のNotebookでs3のデータをトレーニングして、モデルアーティファクトをs3のサンドボックスバケットに格納する
- Validate用Notebookでs3のサンドボックスバケットのモデルアーティファクトをバッチ変換する
- 変換したモデルアーティファクトをダウンロードして、リポジトリにアップロードし、SageMakerのモデルとエンドポイントを更新する
- CI/CDツールを使って、リポジトリとECRコンテナから各環境に向けたSageMakerモデルとエンドポイントを構成する
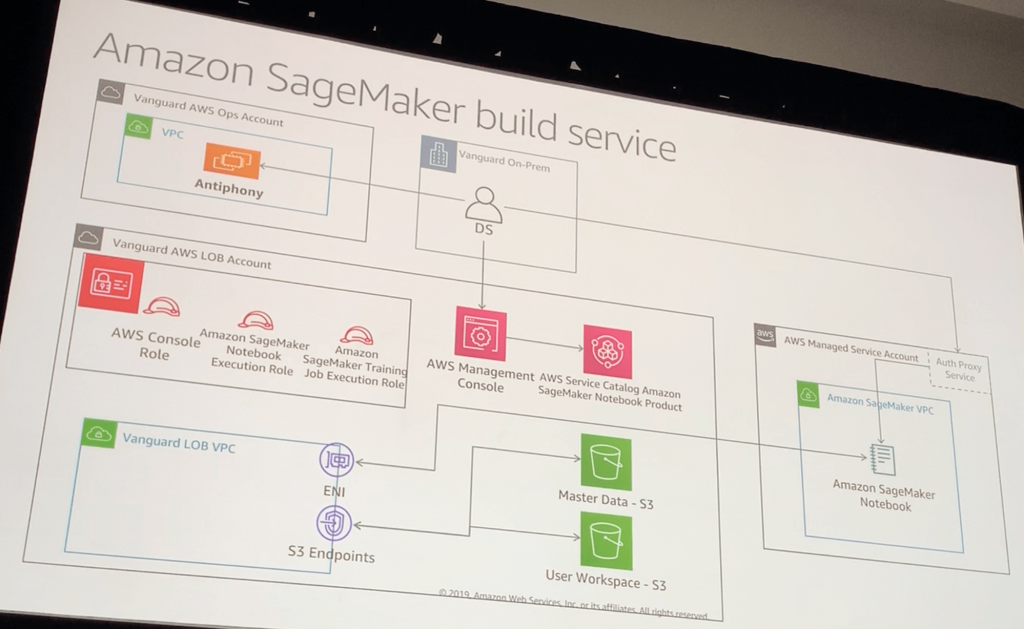
Amazon SageMaker Build sarvice
- Jupyter notebook / Jupyter lab
- AWS Service Catalogを用いた実装
- 簡単にセルフサービスで使える
- 標準化されていて、セキュアである
- (ひろかず注)Enable self-service, secured data science using Amazon SageMaker notebooks and AWS Service Catalog が参考になります
- 認証/認可/監査機能
- Notebook s3インテグレーションとAWS CodeCommit
- Anacondaリポジトリインテグレーション
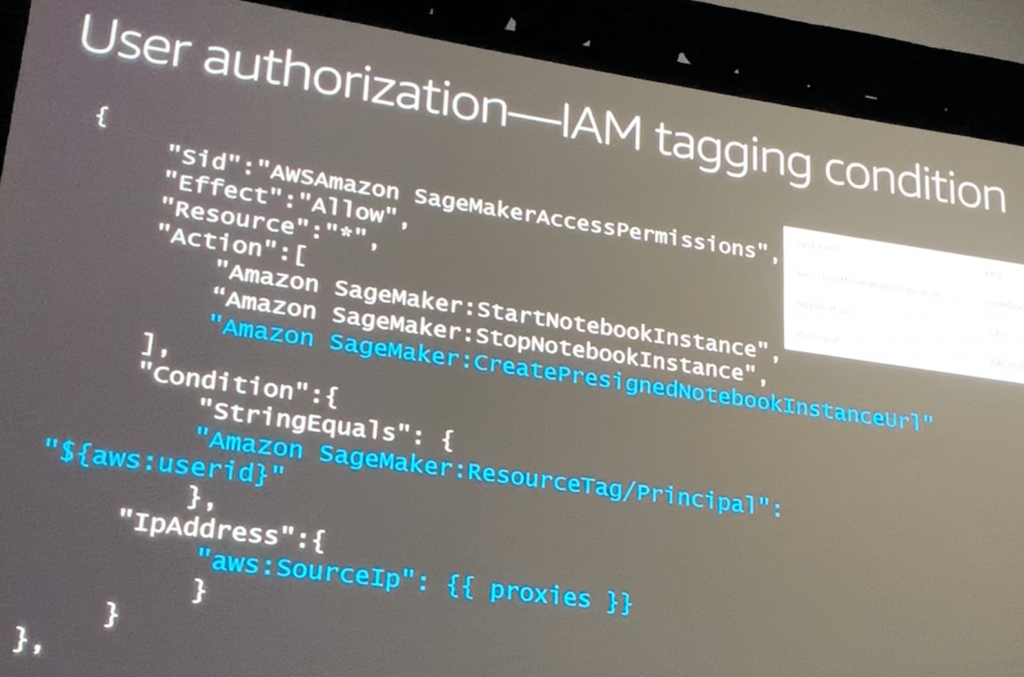
ユーザー認可
- IAMタグとCondition
- 署名付きNotebookインスタンスURLのCreateアクション
- Conditionにて、SageMakerのリソースタグとIPアドレスで制御
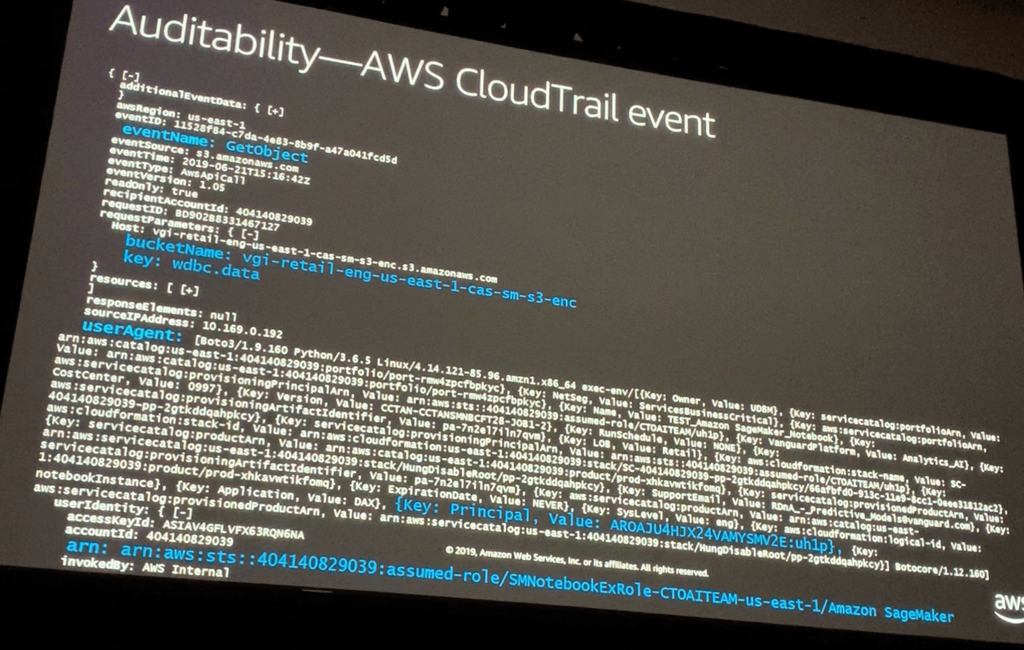
監査機能
etc/init/jupiter-server.confに環境変数AWS_ECECUTION_ENVを設定しておく- 環境変数
AWS_ECECUTION_ENVには、SageMakerのリソースタグを含める - CloudTrailログにはUserAgent内に環境変数
AWS_ECECUTION_ENVの内容が表示される
Amazon SageMaker Train service
- NoteBookがトレーニングジョブを作るのでEC2を立てる
- ハイパーパラメータをチューニングするEC2を立てる
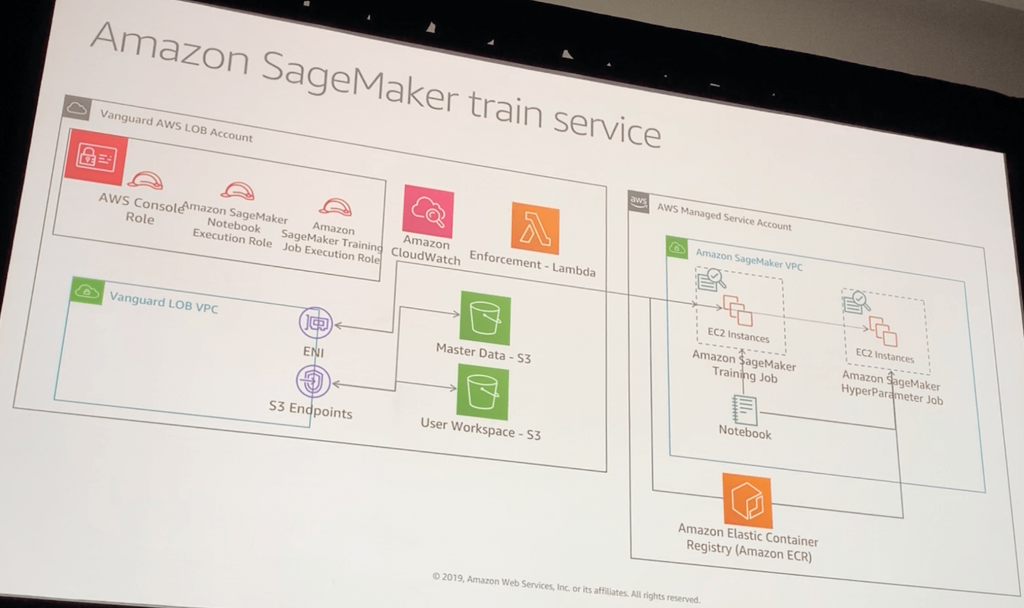
トレーニングジョブの鍵の強制
暗号化
- CMKを用いたs3/EBSのサーバーサイド暗号化
- マルチノードでトレーニングする際の内部通信の暗号化
VPC設定
- インターネットアクセスの禁止
IAM PassRole認可の強制
- NoteBookの実行ロールは、特定のトレーニングジョブ実行ロールを持つトレーニング・ジョブのみを作成できる
モデルの評価
- 作成されたモデルをトレーニングジョブから評価する
- SageMakerモデルはNotebookを通して展開される
バッチインタフェース
- EMRなどのアプリケーションは、ホストするエンドポイントを作成せずに、データ・セット全体を推定のために送信する
- SageMakerモデルは、pipelineを通して展開される
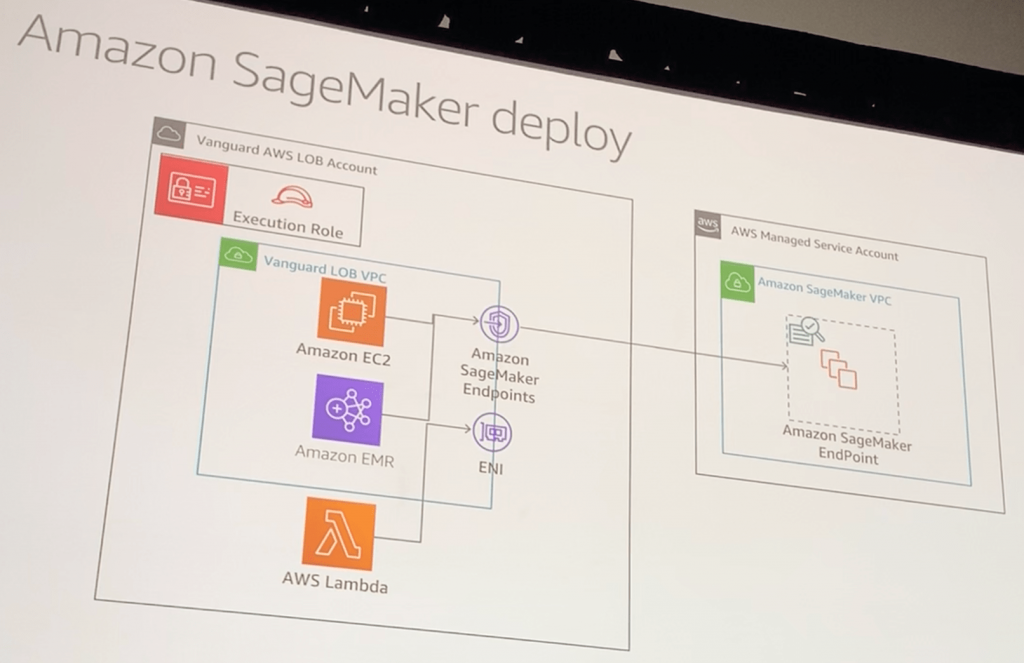
Amazon SageMaker Deploy
- データサイエンティストのリポジトリ(モデルとエンドポイント、Configパラメータ)をレビュー
- レビューを通過したものは、AWS上のCI/CDツールでビルドして、各環境(本番|テスト|検証など)に構成
- 構成したモデルはBlue|Greenのように評価できる
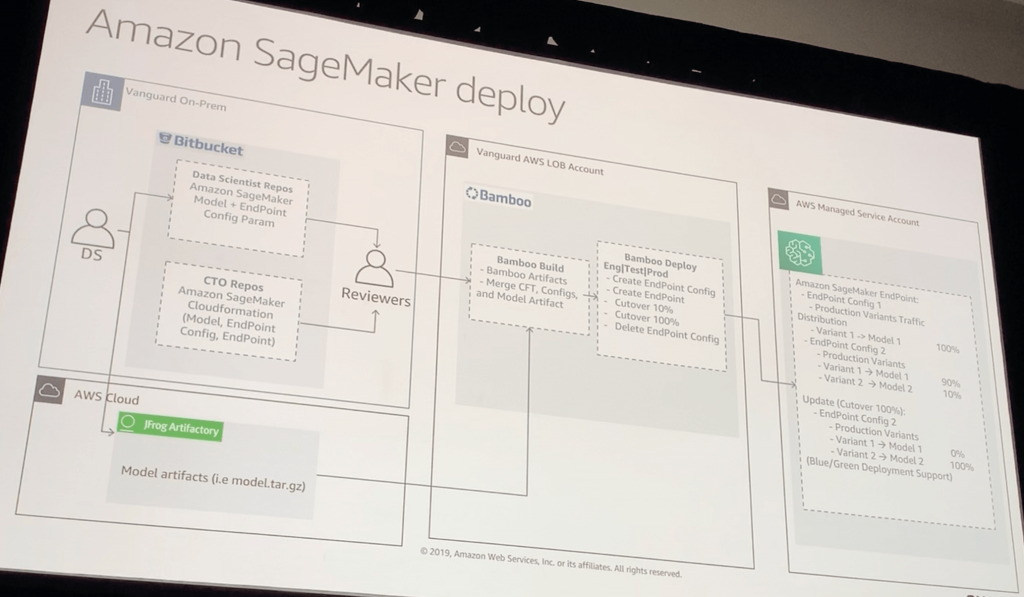
- CI/CDツール(EC2/Lambda)は、SageMakerエンドポイントを通じて、サービス環境にSageMakerのエンドポイントを構成する
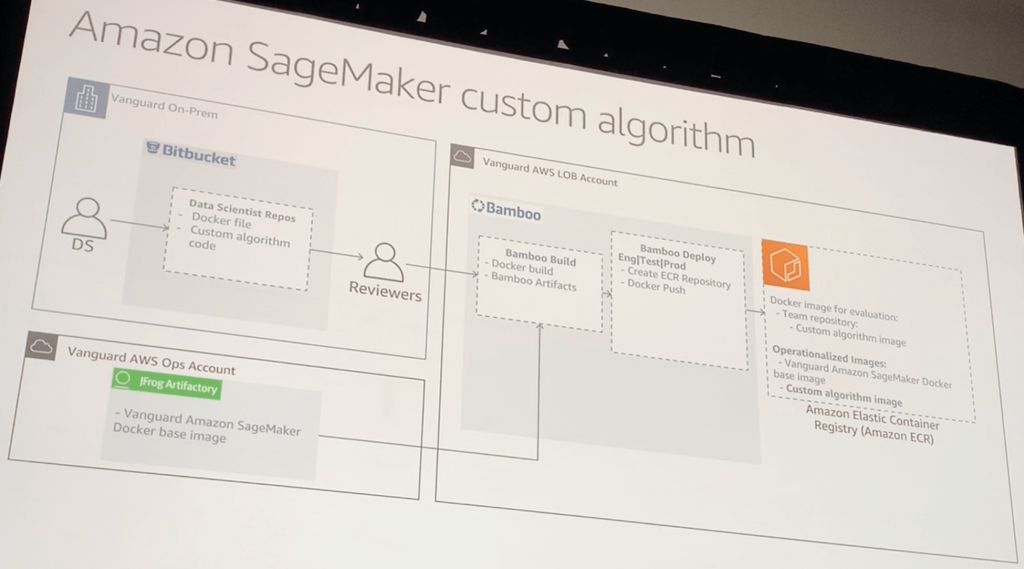
Amazon SageMaker カスタムアルゴリズム
実装方式
- Vanguard社は、Dockerイメージ開発プロセスでPythonとRサポートのAnacondaと標準化されたライブラリ(gunicon, nginx, r-plumberなど)を設定している
- DockerイメージはECRに格納しておく
- サービス環境に展開したNotebookからdocker pullして利用する

Dockerイメージの構成
- データサイエンティストは、Dockerファイルとカスタムアルゴリズムのコードをリポジトリに格納し、レビューを受ける
- CI/CD環境でdocker buildし、各環境(本番|テスト|検証など)のECRにdocker pushする
重要なポイント
要件の明確化
- データサイエンティストがimageをpushして、新しいものを提供できる新しいプロセス
- 一度試してみて、Dockerイメージを検証する流れ
- ユーザーエクスペリエンスとセキュリティ要件を一般ユーザーに適用する
SageMakerはService Catalogで提供する
- Service Catalogは、セルフサービス対応に非常に適している
- ガバナンスプロセスやカスタマイズプロセスについても説明している
構成と運用プロセス
- アプリケーションと開発プロセスは、運用環境に統合するための運用プロセスのインプットになる
- 開発プロセスを運用プロセスにシームレスに統合して、運用を容易にするという部分でまだ課題がある。
クライアント体験へのフォーカス
- データサイエンティストと協力し、データサイエンティストから継続的なフィードバックを得る
- 統合の複雑さに気づいた
- 開発者が本番データにアクセスできる必要がある
- サンプルデータモデルを用意していたが効率的には機能しなかった
- ビジネスの観点で課題を解決する
- 本番データにアクセスできるようにして、ビジネス上の課題を解決できるようにする
- 全てのプロセスは高度に規制された、高度に管理された環境での本番環境と同様である。
- この環境では、どのようなアクションが実行されているかについて、別の監査追跡を行う
- テストデータを可能な限り堅牢なものにするために、本番データのサンプリングとデータの匿名化した少量のサンプリング
- 多くの場合、開発環境で再現しない問題が本番環境で起きる
- できるだけ多くのデータを収集して、最大限のカバレッジを得るようする
AWSプロフェッショナルサービスとSageMakerプロダクトチームとの密接な関係性
- 他社事例と取り組にについての知識共有とブレスト
感想的な何か
- 非常に情報量が多く、消化するのに時間がかかってしまいました。
- AWSは、機械学習の利用推進を方向性として示しているので、SageMakerを始めとする機械学習環境のセキュリティについてはまだまだ整理が必要なようです
- それでも、たくさんの示唆や方法論を得ることができた素晴らしいセッションでした
現場からは以上です。
お疲れ様でした。