
re:Inforce 2023に行ってきたので一筆書きます。
今回は、2日目に集中していた、Amazon Security Lakeのセッションについてです。
お品書き
- [TDR205] Build your security data lake with Amazon Security Lake, featuring IPG
- [TDR333] Gaining insights from Amazon Security Lake
- [PRT233-S] Getting the most out of Splunk Enterprise, OCSF & Amazon Security Lake (sponsored by Splunk)
tl;dr的な何か
- [TDR205] Build your security data lake with Amazon Security Lake, featuring IPG
- Security Lakeは、ログの集約と長期保存、正規化を担う
- Security Lakeそのものは、SIEMの代わりにはならない。分析は別の機能やソリューションで行う
- AWS以外のログは無課金
- [TDR333] Gaining insights from Amazon Security Lake
- Security Lakeを使うメリットは、間違いなく長期的な視点。一カ所への保管と正規化は、長期的にコストを低減する
- ロールアップリージョンは、データをどこに留めておきたいかによって決められる。データレジリエンシーの観点では複数も可能だけど、SIEMも複数必要になる。
- 可視化は、ユースケースに基づいて必要とする人が考えて作る
- [PRT233-S] Getting the most out of Splunk Enterprise, OCSF & Amazon Security Lake (sponsored by Splunk)
- サードパーティのログを取り込むには、OSCF形式であり、Apache Parquet形式のファイルにする必要がある
- データクエリーモードに対応したAdd-Onが数週間以内にリリース予定
- 調査に使うAWSのデータは、Splunkにインジェストせずに外部データとして使うのが合理的になりそう
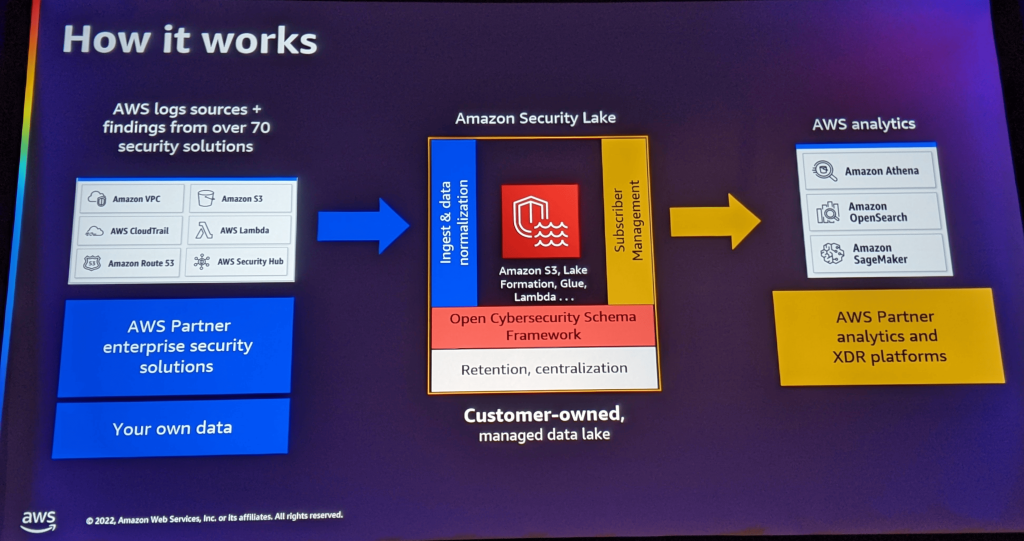
[TDR205] Build your security data lake with Amazon Security Lake, featuring IPG
エンタープライズセキュリティデータの分析の挑戦
セキュリティデータの量が増えていった
- オンプレミス時代は1が月で1GBだったデータ量が、現在はクラウド登場後の分散型アーキテクチャによって爆発的に増え、TBを超え、一部の顧客はPBに及ぶようになった
- 一方で、可視性は飛躍的に向上した
- これまでのソリューションではデータ量とデータ増加量に対応できなくなってきている
- 性能面の問題だけでなく、コストの問題でもある
- また、データは、複数のセキュリティソリューションに散らばっており、それらの保存にかかる費用も生じている
- アクセスコントロールの問題もあり、機密性の高いデータに対して誰がアクセスできるのかを把握するのも大変
非整合的で不完全なデータ
- 各エンティティが生成するログは、形式がバラバラで特定のスキーマに準拠していない
- クラウドは、柔軟性と俊敏性に優れていてすぐに始められるが、形式が異なるログが生じやすい
- これに対応するのは、利用者の責任であり、痛みである
データの直接的な所有権がない
- ログは、セキュリティソリューションの中にあり、手元にはない。保存期間もまちまち
- 他のセキュリティインテリジェンスから切り離されていて、データを利用できない
- データが手元にないので、流行の大規模言語モデルを使うこともできない
- やろうとしても、セキュリティソリューションの中のデータを何度も動かすことになる
セキュリティチームがほしかったもの
中央の正規化されたエンタープライズのログへのアクセス
- 中央へのデータ集積は簡単で、すぐに始められる
- 一方で、データを集めただけでは分析はできない。正規化が必要
- 変化していくログの形式に追従するためにスクリプトを作り込んでいくだけで疲弊してしまい、本来やりたかったことから遠さがってしまう
- Splunkは、スキーマに関するいくつかの知的財産を買い取って、[ 業界のために完全にオープンソース化した(OCSF) ]
- ログを送信する側は、OCSF形式で送信するだけで良くなった

長期保存が可能で、保存コストも抑えられる
- この課題に対応するために、Security Lakeを発表した
- AWSのログだけでなく、他のクラウドプロバイダーやオンプレミスのログをOCSF形式で集積することで、長期保管しながらクエリーできるようになった

解析のための完全な選択の自由を提供
- こうして集約したデータは、Amazon OpenSearch ServiceやAmazon Neptune、サードパーティから買収したAmazon QuickSightのようなAWSの分析ソリューションで分析できるようになった
- 現在では、アイデンティティ管理、EDR、SIEM、ネットワーク・ファイアウォールなど、さまざまなセキュリティ・ベンダーやソリューションと60以上の提携を結んでいる
デモ
- セキュリティレイクのセットアップ
- すべてのリージョンで、すべてのServiceのログを収集するということができる
- 一部のリージョンで、一部のServiceログを収集することもできる
- サブスクライバのアカウントIDと外部IDを設定する
- Quick Sightで可視化する
IPGの事例
- IGPは、マーケティングソリューションの世界的なプロバイダーで、従業員58,000人以上、100以上の国で事業を行っている
ビジネスの優先事項
- セキュリティデータを総合的に理解する
- セキュリティデータの管理と所有権を維持したまま、分析ツールを活用する
- クラウドとオンプレミスのセキュリティアクセス強化
ソリューションの実装
- ログアーカイブアカウントにSecurity Lakeをデプロイ
- AWSネイティブソースのログをSecurity Lakeに統合
- VPC Flowlogs、CloudTrail Logs、Security Hub Findings、Route53 Resolver logs
- サードパーティソースをSecurity Lakeに統合
- データソースとしてWiz、サブスクライバーとしてSplunk
- [ ロールアップリージョン ]の設定
- Athenaでサンプルクエリーの実行(イマここ)
- VPC Flowlogs

ビジネスの成果
- ハイブリッド環境における当社のセキュリティ状況を、より完全に、組織全体で把握することができた
- awsのサードパーティソースからセキュリティ関連データを一元化したセキュリティデータレイクを簡単に作成できた
- IPGのs3バケット内のデータに対する完全な制御と所有権をとりもどした
次にやりたいこと
- インサイトを導き出したい
- OpenSearchの可視化ダッシュボード
- Athenaのカスタムクエリー
- 将来の実装予定
- AWS WAFログ
- Azure AD, Active Directory, Windows Event logs
- Palo AltoのNGFWログ
- Proofpointのログ
コスト
- データ流し込み
- Cloudtrail : 0.75USD/GB
- そのほかのログ : 0.05-0.25USD/GB
- 正規化
- すべてのAWSのログ
- AWS以外のログは無課金!

所感
- AWS以外のログが無課金なのは驚きましたが、正規化(OCSFへの変換)は送信元で行われる前提だと思います
- ログ分析における痛みである、長期保管と真正性の確保と正規化の部分にメスを入れたのは評価に値するとおもいます
- 一方で、ログ分析において最も重要な「何をするか」「どう洞察を得るか」「得られた洞察を使ってどうするか」については、利用者に委ねられたままです
- とはいえ、ログ設計の大変な部分の半分以上がフォローされているとも言えるので、可視化と分析についてはサードパーティ製品をうまく使っていきたいですね
[TDR333] Gaining insights from Amazon Security Lake
- チョークトークです。参加者からの質疑に応答する形で構成されています
- Security Lakeの基本的な話は、前述のTDR205を参照
TDR205に含まれない文脈
- 本当に重視しているのは、自分たちの分析ツールを持ち込めるという点
- 他のSIEMの代わりや排他になるのではなく、個別のSIEM製品に縛られることなくデータが使えるようになることが、データの民主化である
- Srcurity Hubに統合したデータ([ サードパーティ ]を含む)をSecurity Lakeに持ってくる
- OCSF形式へのログ変換は、ETLを噛ますことになる
- 可視化は自分のツールを持ち込む必要がある
- クロスアカウントに対応しているので、データの移動がない
- データアクセスには、2つの方法がある
- Athenaを使った分析。AthenaはGlueを使ってテーブルにクエリーをかけて、結果を抽出できる
- splunkなどのログサブスクライバにリソース共有をすることによる分析
- ログリソースにアクセスできる人を細かく設定できる
- 伝統的な方法では、ログは可視化・分析する中で、さまざまな場所に散在してしまっていたことを、あるべき姿にできる
- ロギングアカウント(集めたログを集積するアカウント)とセキュリティツーリングアカウント(分析ツールが入ったアカウント)を用意する
- ログを分析する人に、セキュリティツーリングアカウントの然るべきツールに対してアクセス権を付与すればいい
- ツールはSplunkでもいいけど、[ MLを使うこともできる ]
質疑
- (注) : 質問者の音声が聞き取れなかった質問は、回答からの推測しています
マルチアカウントではどのような構成になりますか?
- 個別のアカウントのログの保存先をロギングアカウントに設定する
- ロギングアカウントは、ログを分析する側(セキュリティツーリングアカウント)からのアクセス制御ポイントになる
- ロールアップリージョンを使えば、さらに拡大できる
- ちなみに、ロールアップリージョンは複数設定できる
どのような時に複数のロールアップリージョンを使いますか?
- データレジリエンシーが要件の場合、ロールアップリージョンがオプションになる
- s3バケットのクロスリージョンレプリケーションの代替となる
- データを地域化したい場合
- アメリカ人のデータは、アメリカの中に止めておきたい
- ただ、SIEMが一つしかない場合、一つの場所にロールアップリージョンを設定した方がいいかもしれない
- これはあまりよくないかもしれないが、重要なのは、データをどこに置くか、どこにデータを置くかをよりコントロールできるようになったということ
すでに数百ものAWSアカウントのログを一つのS3バケットに統合しています。Athenaを使って分析もしています。Security Lakeを使うことどんな価値を得られますか?
- OCSFで正規化されることで、長期的な視点で価値を得られる
- 新しいソースのログが増えるたびに生じるコストを低減できる
- AWSアカウント作成時のログ収集設定が省略できる
- 設定をオフにすることができる
- まだ何もないのでいらない、まだ集める価値がないなど状況に応じて選択できる
- 新しくログを使いたい人が現れた時に価値を感じられるだろう
他のソリューションは、外部のエージェントから私のデータを収集しますが、どうなりますか?
- 基本的に、私たちはエージェントやコレクターをオンプレミスで持っていないが、パートナーエコシステムがある
- 既存のベンダーが、すでに役に立っている可能性がかなり高い
- AWSの最終的な目標は、「もし誰かがセキュアレイクを採用したいのであれば、既存のプロセスを変更することなく、既存のすべてのベンダーで採用することができる」というもの
- データストレージの問題を解決するだけでなく、それ以上の混乱が生じないようにする
- データ生産者はネイティブにLakeに送信でき、データの消費者やユーザーはネイティブにLakeから消費できる
- オンプレ、クラウド関係なくそうであるが、ログソースによって複数の経路が存在する
- この部分もパートナーシップをリードしていく
- 行き届かないところがあれば、要望を出してほしい
- 長期的なビジョンとしては、導入しても運用の観点に変更は必要ないということ
すべてのデータが入ったのはいいけど、どうすれば常に見えるようになりますか? 知りたいときに尋ねるのではなく、何が起きているかを確認するにはどうしたらいいですか?
- 他のSIEMソリューションと同じように、可視化のビューを作ることになる
- Salesforceをベースにしたクエリーでの可視化が例に挙げられる
- 基本的には、QuickSightをはじめとするあらゆるBIツールで可視化できる
- ダッシュボードは、自分が時間をかけて考えたもので、自分に必要な情報であり、自分との関連性が高いものだから、ダッシュボードは自分で作る
- 他のBIプラットフォームとの統合もある(フェデレーテッドクエリ)
- もう少し運用面に言及すると
- ある発見に対応するため、あるいは調査を行うために、Jupiter Notebookを様々なデータに対して直接実行できる
- 非同期のアラートのためにWorkdayを検討している人もいる
インシデントレスポンスの観点で、どんなメリットがあるのか?
- オンライン上で手動で操作を行うより、ログの中から重要な点を抽出してより迅速に物事を進めることができる
- ログを抽象化するツールを使ってない場合は、生ログを扱うことに長けているかもしれないけど、エグゼクティブは生ログは使わない
- プレゼンテーションの簡略化を行っている
- その活動に対して確信が持てない場合、追加のステップに進むことが簡単に判断できる方法が必要
- 追加ステップでは、レポートに必要な証拠を確認するために生ログにアクセスすることになる
- 要は、ファネル(漏斗)の下から始めるか、上から始めるかの話である
- オンプレミスのデータであろうと、クラウドベンダーのデータであろうとすべてのログを一カ所に集めて全体をクエリできるようにする
- 膨大なデータを照会して、環境全体を可視化することができる
- インシデントレスポンスを行う際にも私は今、意識している
所感
- サードパーティのクラウドサービスからログを持ってくる部分は、コネクタをどうするんだろう?という疑問がありましたが、Security Hubに流してから持ってくるという発想に驚きました。
- 是非試してみたいですね
- ただ、生ログを流すのとは訳が違うことに注意が必要そうです
- 可視化は、ユースケースや必要に基づいて作成するという部分は本質を捉えていると思いました
- なんとなく可視化したいという人は耳が痛かったかもしれません
- それだけに、分析や可視化の具体的な方法論がなかなか見えてこないのは歯がゆいと思います
[PRT233-S] Getting the most out of Splunk Enterprise, OCSF & Amazon Security Lake (sponsored by Splunk)
OCSFとは
- Amazonセキュリティで使用されているバージョンのスキーマは1.0、リリース候補2
- スキーマを拡張して他の種類のデータ型をサポートし、そこから発展させていく予定
- OCSFは、コアスキーマが定義されているが、カスタマイズを可能にする拡張スキーマも用意されているのも利点のひとつ
- 従来のSIEMの場合、イベントをカスタマイズすると、それらのデータスキーマの新しいバージョンにアップグレードするプロセスを管理するのが非常に難しいという課題があった
- スキーマ拡張によって、セキュリティ以外の用途で使うこともできるようになる
- OSI SDFスキーム(?)を使ってデータを取り込むことができるように、データのエンリッチメントも同時に行うようにします。そして、そのデータにさらにコンテキストを追加できる
- プロファイルという概念ができたことで、ACSFの内部から複数の異なるスキーマを組み合わせることができるようになった

データの正規化
- Amazon Security LakeのGAバージョンで、いくつかの主要なデータソースがネイティブにサポートされている
- CloudTrail、VPC Flowlogs、Security Hub、Route53、そしてLambda
- 主要なベンダーのサードパーティサポートも必要であるが、その多くがネイティブではない
- サードパーティのログを取り込むには、OCSF形式に変換する必要がある
- また、取り込むためには、データをApache Parquet形式のファイルにする必要がある
- そのため、サードパーティーのソースとしてSecurity Lakeに統合しようとするベンダーは、OCSFスキーマをサポートし、それをparquet形式のファイルとして提供する必要がある

データアクセスモードとデータクエリーモード
- Security Lakeでは二つのアクセスモードがある
データアクセスモード
- 外部のサブスクライバに対して、特定のデータを選択して、アクセスを許可する機能
- 特定のデータソース内のデータをフィルタリングすることはできない
データクエリーモード
- 特定のデータセットを探すための検索を記述できる
Splunkの場合
- Splunkは、Security Lakeからのデータ取り込みを具体的にサポートしている
- 現時点では、最初の統合レベル、AWSのアドオンによるSplunkへの機能
- データアクセスモードをサポートするバージョン7を導入した
- Security Lakeに入るすべてのデータを取り込み、読み取り、インデックス化できる
- つまり、読み込むデータソースをすべて、または一部だけ選択し、その場でそのデータに対してインデックスを作成できる
- これが機能する理由は、Security LakeのSQSのキューを監視して、Security Lakeが使っているS3バケットに入るすべての権利を監視し、Parquetファイルを組み合わせて、UCSF JSONとしてSwanに取り込み、そして後で使うために検索用にインデックスする
- OCSFデータ自体は、Splunkエンタープライズセキュリティではネイティブにサポートされていない
- Splunkは、共通の情報モデルを使っている。
- 共通の情報モデルは、正規化だけでなく、データアクセスを高速化するためでもある
- そのため、OSCFデータを共通の情報モデルに変換する方法を提供することにした
- このアドオンは、数週間のうちにリリースされ、Splunkベースに公開される予定
- このアドオンでは、データクエリーモードがサポートされる

Splunkの場合 - もう一つのユースケース
- ある種のデータをインジェストしたくない場合
- VPC FlowLogsなどは、脅威検出には使わないが、調査には使いたい
- そんなデータは、インデックス化して取り込む必要はない
- S3の連携検索を使用して、外部データソースに対して検索を実行できる
- Amazonのセキュリティに関しては、Amazon Security LakeとSplunkを一緒に使うことで、すべてを要約してまとめられる
- 一般的なデータソースは、脅威の検知に関連するものと、調査の観点で使用するものとがある
- 一般的に、Mitre攻撃に関するカバレッジを構築することに重点を置いている組織を多く見かけるが、これはおそらくエンドポイントデータソースなどのデータソースに重点を置き、それを使ってSplunkにインジェストすることになるだろう
- 自動攻撃の観点からカバレッジを構築したり、脅威をリアルタイムで検知してモニタリングしたりするユースケースに対して、VPCフローログのデータは脅威検知の観点ではあまり価値がなく、IOCマッチやその後の調査の観点でより関連性が高いので、セキュリティレイクに保管しておき、検知した後にアドホックな調査のために5つの統合検索を使用することが理にかなっているかもしれない

これから
- 長期的には、Splunkのインジェストアクションやエッジプロセッサーなどの機能を使って、Sparkに入るデータとSecurity Lakeなどの外部データレイクに入るデータをルーティングフィルタすることで、データの保存場所を選択することができ、さらに連携検索などの機能を使って外部データソースの検索を開始できる。
所感
- SplunkとSecurity Lakeの関係性がよくわかるセッションでしたね
- アドオンが公開されたら、是非試してみたいと思います!
今回はここまでです。
お疲れ様でした。